



Das Entwerfen neuer optischer Systeme von Grund auf kann eine entmutigende Aufgabe sein, besonders wenn das System, das wir erstellen wollen, eines ist, das wir richtig machen müssen, bevor überhaupt etwas gebaut werden kann, da die kritischen Komponenten einfach noch nicht existieren. Es ist lediglich eine Vorstellung in unserer Vorstellungskraft und es gehört actually zu unseren Aufgaben, sie zu definieren. Ähnliche Situationen werden auftreten, wenn wir verschiedene Entwürfe untersuchen und lernen wollen, wie die Dinge wirklich funktionieren, bevor wir uns an die tatsächliche Realisierung machen.
Stellen wir uns das mal vor. Sie müssen die Anforderungen für ein System finden, das wir nie zuvor studiert haben, und wenn es ein wissenschaftliches Paper gibt, das vielleicht mit dem zu tun hat, was wir brauchen, werden wir es dann überhaupt finden? Es ist nicht ungewöhnlich, dass wir das Rad neu erfinden. Dirac hat die Clifford-Algebra neu erfunden, als er die quantenmechanischen Gleichungen für das Elektron herleitete, also passiert so etwas offensichtlich den Besten von uns. Gehen wir also einfach davon aus, dass die Verantwortung letzten Endes bei uns liegt, egal wie man es dreht.
Die beste Strategie an diesem Punkt wäre, ein Modell zu erstellen - eine Art Karte, aber nicht irgendeine Karte; sie muss detailliert genug sein, um durch alle wichtigen Drehungen und Wendungen (sprich: Freiheitsgrade) zu navigieren, aber nicht so kompliziert, dass wir den Wald vor lauter Bäumen nicht mehr sehen. Hier liegt unsere erste Herausforderung: Wenn diese Maschine nicht ein enger Verwandter von etwas ist, das wir bereits beherrschen, ist unsere Karte eher eine Vermutung als ein Evangelium. Wir tappen ein wenig im Dunkeln, welche Pfade (Freiheitsgrade) die relevanten sind und welche nur Details darstellen.
Ohne den richtigen Kompass (die richtigen Werkzeuge), um sich in der Komplexität zurechtzufinden, laufen wir Gefahr, unsere Karte zu stark zu vereinfachen und uns mehr von unserer Vorstellungskraft als vom tatsächlichen Terrain leiten zu lassen.
Reduzierung der Komplexität
Eine Möglichkeit, dies zu bewerkstelligen, die sich als gut erwiesen hat, ist die Anwendung einer bekannten mathematischen Entwicklung um den idealen Zustand des untersuchten Systems, im Wesentlichen eine Maclaurin-Entwicklung. Da das Werkzeug, das wir suchen, uns von unseren eigenen mentalen Beschränkungen befreien soll, muss es uns erlauben, unser System mit einer großen Anzahl unabhängiger Variablen zu untersuchen.
Es gibt verschiedene Möglichkeiten, dies anzugehen, aber eine, die sich als sehr gut erwiesen hat, ist das sogenannte Latin Hypercube Sampling (LHS), das manchmal auch als raumfüllendes Design bezeichnet wird.
Die Erstellung eines LHS dauert zwar einige Zeit, ist aber in den meisten Fällen normalerweise weniger als ein paar Minuten, auch wenn die Anzahl der unabhängigen Variablen groß ist. Die Zeit für die Erstellung eines LHS wächst linear mit der Anzahl der Variablen und mit der 3. Potenz mit der Anzahl der Stichproben. Glücklicherweise handelt es sich hierbei nur um eine polynomiale Komplexität, oder “einfach”, wenn man die Leute vom Bereich der Komplexitätstheorie fragt.
Ein Beispiel, wo eine große Anzahl von Freiheitsgraden interessant sein könnte, ist, wenn wir die Spezifikation für ein optisches System ableiten wollen und die Freiheitsgrade die Zernike-Polynomkoeffizienten sind.
Die LHS liefert uns eine Reihe von gleichmäßig verteilten Stichproben in einem mehrdimensionalen Raum, aber es liegt immer noch an uns, die richtige Frage zu stellen, und in diesem Fall gibt es praktisch keine falschen Fragen.
So, zum Beispiel können anhand dieses Samplesetzes Simulationen eingerichtet werden, die die Varianz einer Eigenschaft untersuchen, oder man kann simulieren, wie eine deterministische Eigenschaft von unseren Freiheitsgraden abhängt. Beides kann sehr wertvoll sein, aber bevor wir uns damit näher beschäftigen, sprechen wir darüber, wie wir einige Ergebnisse zum Analysieren erhalten.
Zweite Ordnung Expansion
So simpel dies auch klingen mag, es ist ein sehr wertvoller Ansatz, der zu Einsichten führt, die nicht selten zu Aha-Erlebnissen werden.
Von der LHS (Least-squares Hyperspectral Imaging) haben wir eine Punktmenge, und anhand dieser Stichprobenpunkte in unserem mehrdimensionalen Problem führen wir eine gleich große Anzahl von Simulationen durch, um für jeden einzelnen ein numerisches Ergebnis zu erhalten. Dies alles getan zu haben, ist jedoch nicht sehr erhellend. Wir müssen diese Komplexität reduzieren. Wir müssen all diese Simulationen, die leicht mehrere Tausend betragen können, in etwas Fassbares zusammenfassen, etwas, das sozusagen die Spreu vom Weizen trennt.
Der Weg dazu ist der Versuch, unsere Ergebnisse durch eine Erweiterung zweiter Ordnung auszudrücken,
Das ist sehr ähnlich zu der Art und Weise, wie wir eine Maclaurin-Entwicklung ausdrücken würden, aber der Punkt ist, dass der Gradient und die Hesse-Matrix immer noch unbekannt sind und wir sie finden müssen. Können wir das tun?
Ja, das können wir. Wir haben genügend Informationen, und die Ermittlung des Koeffizienten von v und H ist ein lineares Problem. Für eine 2 DOF haben wir 1 Unbekannte "c", zwei Unbekannte im linearen Term "v" und 2 + 1 in "H", denn H ist symmetrisch. Für 3 DOF haben wir 1 + 3 + 3 + 2 + 1 und so weiter. Das ist einfach lineare Algebra. Unsere Tausenden von Simulationen und die Pseudo-Inverse von More Penrose werden uns diese Unbekannten schneller liefern, als wir "numerische Lösung" sagen können.
Zu den guten Sachen
Und es ist jetzt, dass die interessanten Dinge beginnen. Vorausgesetzt, unsere Erweiterungen zweiter Ordnung sind gut, haben wir oft Tausende von Simulationen in ein Modell reduziert, das wir nun noch weiter aufschlüsseln können.
Das Erste, was man normalerweise nach dem Erhalt der Erweiterung tun würde, ist zu prüfen, wie gut diese Erweiterung die Tausenden von Simulationsergebnissen wiedergibt. Häufig liegt die Übereinstimmung zwischen dem Modell und den Simulationen bei über 99,1 %. Ich würde 95,1 % als gerade noch brauchbar ansehen, aber das übliche Ergebnis liegt bei etwa 99,1 % oder besser. Das hängt natürlich davon ab, wie die zugrunde liegende Eigenschaft aussieht und ob unser numerisches Modell für eine statistische Eigenschaft ausgelegt ist oder nicht.
Bevor wir mit diesem Modell gespielt haben, wussten wir das nicht, aber ich habe noch keinen Fall gefunden, der nicht auf eine Weise transformiert werden konnte, die diese Erweiterung ermöglicht, um im Wesentlichen die gesamte Varianz aus unseren Simulationen zu erfassen.
Analyse der Expansion
Jetzt kommen wir zu dem Teil, wo wir die Früchte unserer harten Arbeit ernten können. Es gibt in der Regel drei Arten von Ergebnissen: Entweder wird die Ausdehnung durch den linearen Term oder den quadratischen Term dominiert oder sie ist gemischt, was eigentlich recht interessant ist, weil es uns sagt, dass unsere Ausdehnung nicht um ein Minimum herum ist.
Wenn der lineare Term dominiert, dann war's das wohl. Es gibt keine Wechselwirkungen zwischen den DOFs, über die man reden müsste. Der Fall ist abgeschlossen. Unser System war einfach, und wenn wir es vorher nicht verstanden haben, so wissen wir es jetzt.
Interessanter wird es, wenn der Term zweiter Ordnung die Expansion dominiert, denn jetzt gibt es mehr zu lernen. Hier sollte man auf jeden Fall mehr lineare Algebra in Anspruch nehmen und Folgendes umschreiben H als,
mit Hilfe der Singulärwertzerlegung (Singular Value Decomposition, kurz: SVD).
Wenn Sie so weit gekommen sind und sich dafür entscheiden, diese Gelegenheit nicht zu nutzen, wäre das gleichbedeutend damit, dass Neo die blaue Pille schluckt und sich dafür entscheidet, zu schlafen und zu glauben, was er glauben will. Nehmen Sie niemals die blaue Pille.
Wenn Ihr System in Form einer Matrix zweiter Ordnung ausgedrückt werden muss, müssen Sie im Wunderland bleiben und sich von der SVD zeigen lassen, wie tief das Kaninchenloch ist.
Dies ist nicht nur ein theoretisches Zahlenspiel. Sie müssen dies möglicherweise bei der Entwicklung Ihrer Optik wissen, denn es sagt Ihnen nicht nur, dass bestimmte Aberrationskombinationen zusammen optimiert werden müssen, sondern die Diagonalelemente von Σ sagen Ihnen auch, wie wichtig jede dieser Kombinationen wirklich ist, was ein unschätzbarer Hinweis darauf ist, was die Merit-Funktion am stärksten unterdrücken sollte.
Wie sieht es nun mit dem gemischten Fall aus, bei dem sowohl der lineare als auch der quadratische Teil wesentlich zum Modell beitragen? Dieser Fall ist wirklich interessant, weil er uns zeigt, dass das System entgegen unserer ursprünglichen Annahme nicht um den idealen Zustand herum erweitert wurde.
Dieser Fall erfordert ein wenig Vorsicht, da die Lösung modellspezifisch ist und selbst dann ein neues Minimum außerhalb des mit den anfänglichen Stichprobenpunkten abgetasteten Volumens aufweisen kann. Das kann immer noch in Ordnung sein, aber darauf ist kein Verlass.
Es ist Zeit für ein Beispiel
Nehmen wir an, wir wenden diese Theorie auf etwas wie die Faserkopplung an. Bleiben wir im Geiste, dass wir nicht wissen, wie es funktioniert, verwenden wir die Zernike-Polynome als Freiheitsgrade und berechnen als Testfunktion die Einfügedämpfung als Funktion unserer Freiheitsgrade.
Zuerst würden wir definieren, wie viele Freiheitsgrade (DOF) wir untersuchen möchten. Nehmen wir an, wir stoppen bei Z16. Wir wissen, dass Z1 normalerweise keine Rolle spielt, die folgenden jedoch, also 15 DOF.
Als nächstes generieren wir 1024 Stichprobenpunkte über 15 Freiheitsgrade mithilfe der LHS. Die LHS generiert normalerweise Stichprobenpunkte über einen Hyperwürfel, daher müssen wir diese Werte auf etwas Sinnvolles skalieren. Wenn wir nichts über das Thema wissen, sollten wir wahrscheinlich klein anfangen, wirklich klein. Dann vielleicht den Prozess wiederholen, bis wir feststellen, dass das von uns berechnete Modell nicht mehr gut zu den Daten passt, oder bis wir einen Wertebereich erreichen, der für unser System relevant ist.
Nun machen wir einen kleinen Zeitsprung und 1024 Simulationen der Einfügedämpfung später haben wir unsere Funktion f(x,....) und etwas zu modellieren. (Diese Simulation ging von einer Apodisation von 2 und einem Gaußschen Grundmodus aus. Dieser Blog befasst sich nicht so sehr mit Singlemode-Fasern, daher bitten wir um Nachsicht bezüglich der vereinfachten Annahmen über Singlemode-Fasern.)
Sobald wir die Koeffizienten von c, v, und Hkönnen wir uns ansehen, wie das Modell unsere Simulationen erfasst hat,
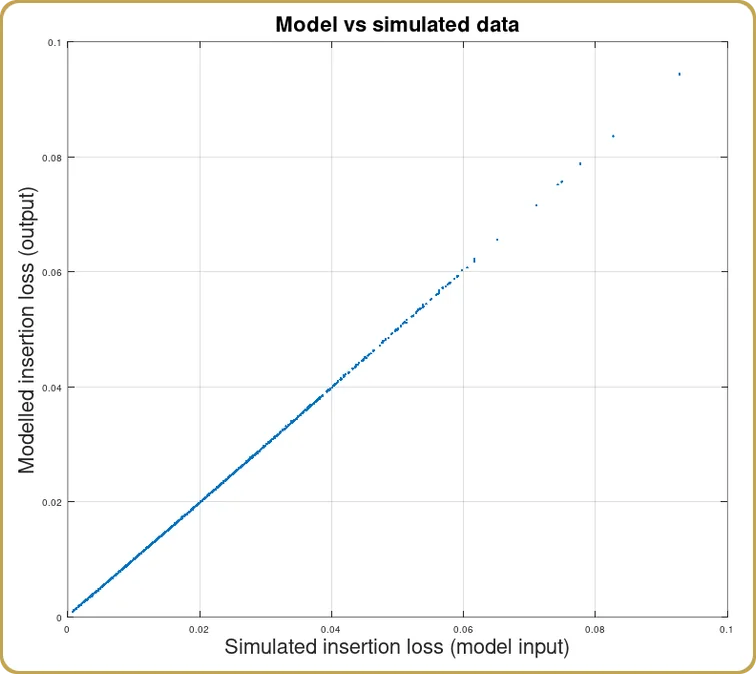
Wie erwartet, haben wir eine gute Korrelation zwischen den Simulationen und der Modellentwicklung erzielt. Da die physikalische Optik nur durch das Überlappungsintegral beschrieben wird, war das zu erwarten. Dies soll schließlich ein Beispiel zum Lernen sein.
Nun können wir uns auch ansehen, wie viel von dieser Korrelation auf den linearen Term zurückzuführen ist,
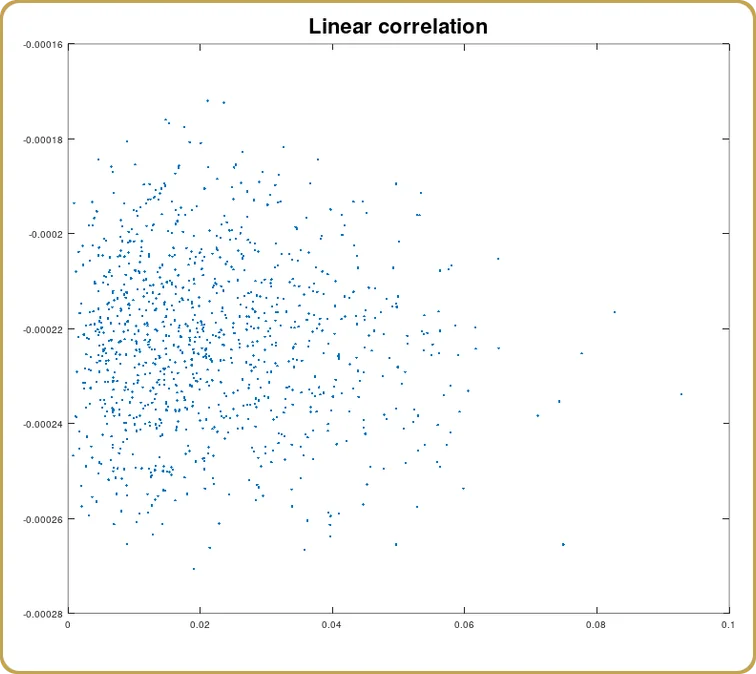
Und wieder ist, wie erwartet, die Korrelation (statistisch) null. Wir haben etwas modelliert, das ein Minimum bei null Aberrationen hat. Der lineare Teil wird erwartungsgemäß verschwinden. Schauen wir uns also nun den quadrierten Term an.
Ich hoffe, dass es mittlerweile ziemlich offensichtlich ist, dass wir die Singular Value Decomposition verwenden werden, erinnern Sie sich an die rote Pille, richtig? Also, wir werfen unsere H in die SVD, und das erste, was untersucht werden muss, sind die Singulärwerte,
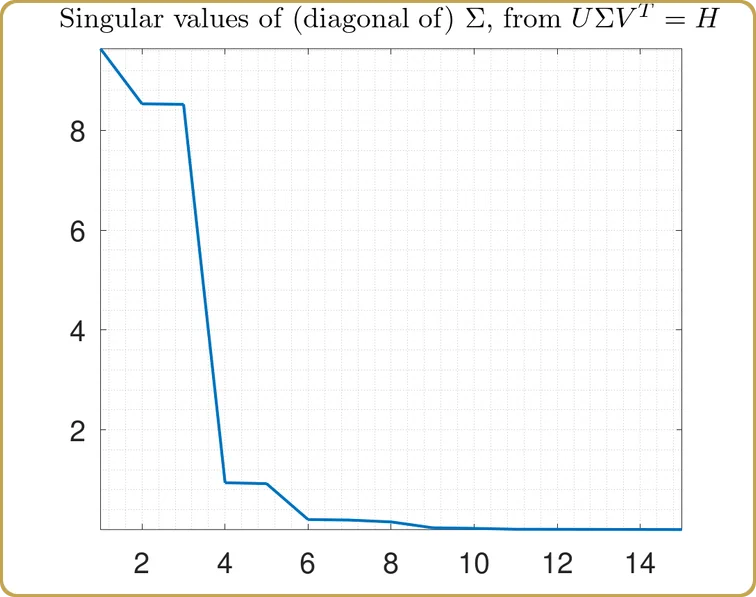
Die tatsächlichen Werte auf der Y-Achse sind nicht so interessant, denn sie hängen schließlich vom Volumen unseres Testhyperwürfels ab, mit dem wir unser Problem abgetastet haben. Interessanter ist die Struktur. Unser Problem wurde auf fast 3 unabhängige Variablen reduziert, plus 2 deutlich weniger wichtige. Schauen wir mal,
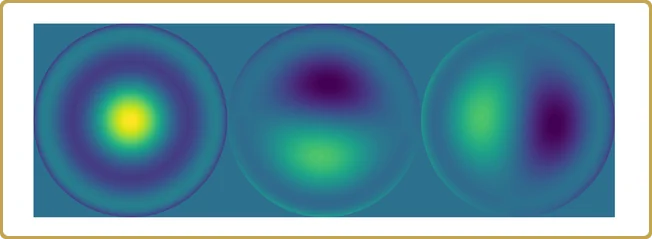
Zeit für ein Resümee.
Wir begannen mit 1024 simulierten Werten über 15 Dimensionen von etwas, über das wir (vorgegeben haben) nichts wussten, und endeten mit 3 wesentlichen Beiträgen zu einer Eigenschaft, die wir verstehen wollten.
Dies ist kein ungewöhnliches Ergebnis bei dieser Art von Analyse. Vielleicht ist die Korrelation nicht ganz so gut wie in diesem konstruierten Beispiel, aber mit einer gewissen Transformation der Daten kann das Modell zweiter Ordnung im Wesentlichen die gesamte Varianz der Simulation erfassen.
Der vielleicht wertvollste Aspekt dieser Art von Analyse ist, dass wir eine viel größere Anzahl von Freiheitsgraden in Angriff nehmen können und uns nicht durch unsere Fähigkeit, die Komplexität zu entwirren, einschränken lassen. Oder um bei der Kartenmetapher zu bleiben: Es gibt keine Bäume. Wir sehen nur Wälder und Hügel. Von diesem Aussichtspunkt aus ist das Gesamtbild alles, was zählt, und alles, was wir dafür bezahlt haben, war Computerzeit.
Werkzeugkasten für Systemingenieure
Hier gibt es ein praktisches Werkzeug für Systemingenieure, die einfach eine der vielen beweglichen Teile in ihrer (normalerweise ziemlich großen) Excel-Tabelle von Systemkompromissen erfassen müssen.
Es kommt nicht oft vor, dass man eine Analyse findet, die so lehrbuchmäßig ist wie die hier vorgestellte. Ich schreibe dies, weil ich gerade auf einen Fall gestoßen bin, bei dem es weder eine lineare Korrelation noch eine Korrelation zweiter Ordnung gibt, die vollständige Erweiterung jedoch dennoch 96%-97% der Daten erfasst. Das ist nicht ungewöhnlich, wenn man Variablen miteinander kombiniert, die physikalisch nicht miteinander verbunden sind. In der Regel lassen sie sich nicht gut gemeinsam modellieren.
Die Erweiterung erfasste jedoch immer noch Informationen, die wir als Systemingenieure nutzen können, wenn wir zwischen Parametern, die wir in unseren (sagen wir) optischen Simulationen erfassen, und den Auswirkungen, die diese Parameter auf andere Systemeigenschaften haben können, abwägen müssen. Viele solcher Beispiele.
Weiter gehend
Warum haben wir bei einer Expansion 2. Ordnung aufgehört? Nun, es gibt “Gründe”. Die nächste Ordnung wird durch einen symmetrischen Rang-3-Tensor beschrieben. Wir können die Komponenten dieses Tensors immer noch extrahieren, weil das Problem der kleinsten Quadrate, das diese Komponenten mit unseren Daten verbindet, immer noch linear ist.
Wir verlieren aber auch einige Dinge. Es gibt beispielsweise keine SVD für Tensoren. Es gibt jedoch “neuere” mathematische Arbeiten (wenn man 2005 als neu bezeichnet, aber ich habe damit vor 2005 begonnen), die weitere Einblicke in die Eigenschaften komplexer Systeme bieten könnten, wie z. B. Eigenwerte und Eigenvektoren für Tensoren.
Sollten Sie das zu esoterisch finden, und ich verstehe das vollkommen, dann wird eine Expansion 3. Ordnung garantiert mehr Varianz in Ihren Daten erfassen als eine Ausdehnung 2. Ordnung. Wenn Sie diese magische Funktion nur in Ihrer Excel-Tabelle benötigen, können Sie sie zumindest haben.