



Concevoir de nouveaux systèmes optiques à partir de zéro peut être une tâche intimidante, surtout si le système que nous essayons de réaliser est l'un de ceux que nous devons réussir avant que quoi que ce soit ne puisse être construit, car les composants critiques n'existent tout simplement pas encore. Ce n'est qu'un fantasme de notre imagination, et cela fait en fait partie de notre tâche de le définir. Des situations similaires se présenteront lorsque nous explorerons différentes conceptions et que nous voudrons comprendre comment les choses fonctionnent réellement avant d'entreprendre la tâche de les construire.
Alors, imaginons la situation. Vous devez trouver les exigences pour un système que nous n'avons jamais étudié auparavant, et s'il existe un article scientifique qui est peut-être lié à ce dont nous avons besoin, allons-nous même le trouver ? Il n'est pas rare que nous réinventions la roue. Dirac a réinventé l'algèbre de Clifford lorsqu'il a dérivé les équations quantiques de l'électron, donc évidemment, cela arrive aux meilleurs d'entre nous. Alors supposons simplement que, quoi qu'il en soit, la responsabilité nous incombe.
La stratégie à adopter à ce stade consisterait à élaborer un modèle - une sorte de carte, mais pas n'importe laquelle ; elle doit être suffisamment détaillée pour permettre de naviguer dans tous les méandres essentiels (lire : degrés de liberté), sans pour autant être trop complexe pour que l'on ne voie pas la forêt dans les arbres. C'est là que réside notre premier défi : à moins que cette machine ne soit un proche cousin d'une machine que nous maîtrisons déjà, notre carte tient plus de la conjecture que de l'évangile. Nous ne savons pas très bien quels chemins (degrés de liberté) sont les plus importants et quels sont ceux qui ne sont que des détails.
Sans la bonne boussole (les bons outils) pour naviguer dans la complexité, nous risquons de simplifier à l'extrême notre carte, limités davantage par notre imagination que par le terrain réel.
Réduire la complexité
Une façon de gérer cela, qui s'est avérée efficace, est d'employer un développement mathématique bien connu autour de l'état idéal du système étudié, essentiellement un développement de Maclaurin. Puisque l'outil que nous recherchons est celui qui libère notre analyse de nos propres limites mentales, il doit être capable de sonder notre système avec un grand nombre de variables indépendantes.
Il existe différentes manières d'aborder cela, mais une méthode que j'ai trouvée très efficace est l'échantillonnage par hypercube latin (LHS), parfois aussi appelé plan de remplissage de l'espace.
La génération d'un plan d'expériences LHS prend du temps, mais dans la plupart des cas, elle est généralement inférieure à quelques minutes, même si le nombre de variables indépendantes est important. Le temps nécessaire à la génération d'un LHS augmente linéairement avec le nombre de variables et à la puissance 3 avec le nombre d'échantillons. Heureusement, il s'agit seulement d'une complexité polynomiale, ou “ facile ” si vous posez la question à des spécialistes de la complexité algorithmique.
Un exemple où un grand nombre de degrés de liberté peut être intéressant est lorsque l'on souhaite dériver la spécification d'un système optique, et que les degrés de liberté sont les coefficients du polynôme de Zernike.
La LHS nous donne un ensemble d'échantillons uniformément distribués dans un espace multidimensionnel, mais il nous appartient toujours de poser la bonne question et, dans ce cas, il n'y a pratiquement pas de mauvaise question.
Donc, par exemple, en utilisant cet ensemble d'échantillons, on peut mettre en place des simulations qui sondent la variance d'une propriété, ou on peut simuler comment une propriété déterministe dépend de nos DOF. Les deux peuvent être très précieux, mais avant de plonger plus profondément dans cela, parlons de la manière d'obtenir des résultats à analyser.
Développement d'ordre deux
Aussi simple que cela puisse paraître, il s'agit d'une approche très précieuse qui offre des aperçus qui se transforment souvent en moments d'émerveillement.
De la partie gauche, nous avons un ensemble de points, et en utilisant ces points d'échantillonnage dans notre problème multidimensionnel, nous exécutons un nombre égal de simulations pour obtenir un résultat numérique pour chacun. Cependant, après avoir tout cela fait, ce n'est pas très éclairant. Nous devons réduire cette complexité. Nous devons résumer toutes ces simulations, qui pourraient facilement être plusieurs milliers, en quelque chose que nous pouvons comprendre, quelque chose qui, pour ainsi dire, permet de séparer le bon grain de l'ivraie.
Pour ce faire, nous essayons d'exprimer nos résultats à l'aide d'une expansion du second ordre,
C'est très similaire à la manière dont nous exprimerions un développement de MacLaurin, mais le fait est que le gradient et le Hessien sont toujours inconnus, et nous devons les trouver. Pouvons-nous le faire ?
Oui, nous pouvons. Nous avons plein d'informations, et trouver le coefficient de v et H est un problème linéaire. Pour un 2 DOF, nous avons 1 inconnue "c", 2 inconnues dans le terme linéaire "v" et 2 + 1 dans "H" parce que H est symétrique. Pour 3 DOF, nous avons 1 + 3 + 3 + 2 + 1 et ainsi de suite. Il s'agit simplement d'algèbre linéaire. Nos milliers de simulations et le pseudo-inverse de More Penrose nous donneront ces inconnues plus vite que nous ne pouvons dire "solution numérique".
Vers les bonnes choses
Et c'est maintenant que les choses intéressantes commencent. En supposant que nos développements du second ordre sont bons, nous avons réduit souvent des milliers de simulations en un modèle que nous pouvons maintenant commencer à démonter encore plus.
La première chose que l'on fait généralement après avoir obtenu l'extension est de vérifier dans quelle mesure celle-ci reproduit les milliers de résultats simulés. Très souvent, la corrélation entre le modèle et les simulations est supérieure à 99,1 %. Je considérerais un résultat de 95,1 % comme à peine utile, mais le résultat habituel se situe autour de 99,1 % ou mieux. Cela dépendra bien sûr de la nature de la propriété sous-jacente, et du fait que notre modèle numérique porte ou non sur une propriété statistique.
Avant que nous jouions avec ce modèle, nous ne le savions pas, mais je n'ai pas encore trouvé de cas qui ne puisse être transformé d'une manière qui permette à cette expansion de capturer toutes les variations de nos simulations, essentiellement.
Analyse de l'expansion
Nous arrivons maintenant à la partie où nous pouvons récolter les fruits de notre dur labeur. Il y a typiquement trois types de résultats, soit l'expansion est dominée par le terme linéaire, soit par le terme carré, soit elle est mixte, ce qui est en fait assez intéressant car cela nous indique que notre expansion n'est pas autour d'un minimum.
Si le terme linéaire domine, je suppose que c'est tout. Il n'y a pas d'interactions entre les DOF. L'affaire est close. Notre système était simple, et si nous ne l'avions pas compris avant, nous le comprenons certainement maintenant.
La situation devient plus intéressante lorsque le terme de second ordre domine l'expansion, car il y a alors plus à apprendre. Ce qu'il faut faire ici, c'est certainement faire appel à plus d'algèbre linéaire et réécrire H comme,
à l'aide de la décomposition en valeurs singulières (SVD).
Si vous êtes arrivé jusqu'ici et que vous choisissez de ne pas saisir cette opportunité, cela équivaudrait à ce que Néo prenne la pilule bleue, choisisse de dormir et de croire ce qu'il veut croire. Ne prenez jamais la pilule bleue.
Si votre système doit être exprimé en termes de matrice du second ordre, vous devez rester au pays des merveilles et laisser la SVD vous montrer la profondeur du trou de la souris.
Il ne s'agit pas d'un simple jeu de chiffres théorique. Vous pourriez avoir besoin de le savoir lors de la conception de vos optiques car, non seulement cela vous indique que certaines combinaisons d'aberrations doivent être optimisées ensemble, mais les éléments diagonaux de Σ vous indiquent également l'importance réelle de chacune de ces combinaisons, ce qui est une indication inestimable de ce que la fonction de mérite devrait le plus supprimer.
Qu'en est-il du cas mixte, où la partie linéaire et la partie carrée contribuent toutes deux de manière significative au modèle ? Ce cas est vraiment intéressant car il nous indique que, contrairement à ce que nous pensions initialement, le système n'a pas été étendu autour de l'état idéal.
Ce cas nécessite un peu de prudence car la solution dépend du modèle, et même ainsi, elle peut indiquer un nouveau minimum en dehors du volume sondé par le premier ensemble de points d'échantillonnage. Cela peut toujours être acceptable, mais cela ne peut pas être tenu pour acquis.
C'est l'heure de l'exemple
Supposons que nous appliquions cette théorie à quelque chose comme le couplage de fibres. Dans l'esprit de ne pas savoir comment cela fonctionne, nous utilisons les polynômes de Zernike comme degrés de liberté, et, comme fonction test, nous calculons la perte d'insertion en fonction de nos degrés de liberté.
Premièrement, nous définirions combien de DL nous intéressons à étudier. Disons que nous nous arrêtons à Z16. Nous savons que Z1 n'a généralement pas d'importance, mais ceux qui suivent en ont, donc 15 DL.
Ensuite, nous générons 1024 points d'échantillonnage sur 15 degrés de liberté en utilisant la méthode LHS. La méthode LHS génère généralement des points d'échantillonnage sur un hypercube, nous devons donc adapter ces valeurs à quelque chose de raisonnable. Si nous ignorons tout du sujet, alors nous devrions probablement commencer petit, vraiment petit. Ensuite, peut-être répéter le processus jusqu'à ce que nous constations que le modèle que nous calculons ne correspond plus très bien aux données, ou jusqu'à ce que nous atteignions une plage de valeurs que nous croyons pertinente pour notre système.
Maintenant, nous sautons un peu dans le temps et 1024 simulations de perte d'insertion plus tard, nous avons notre fonction f(x,....) et quelque chose à modéliser. (Cette simulation a supposé une apodisation de 2 et un mode fondamental gaussien. Ce blog ne porte pas tant sur les fibres monomodes, alors excusez les hypothèses simplifiées concernant les fibres monomodes.
Une fois que nous aurons trouvé les coefficients de c, v, et HNous pouvons ainsi voir comment le modèle a pris en compte nos simulations,
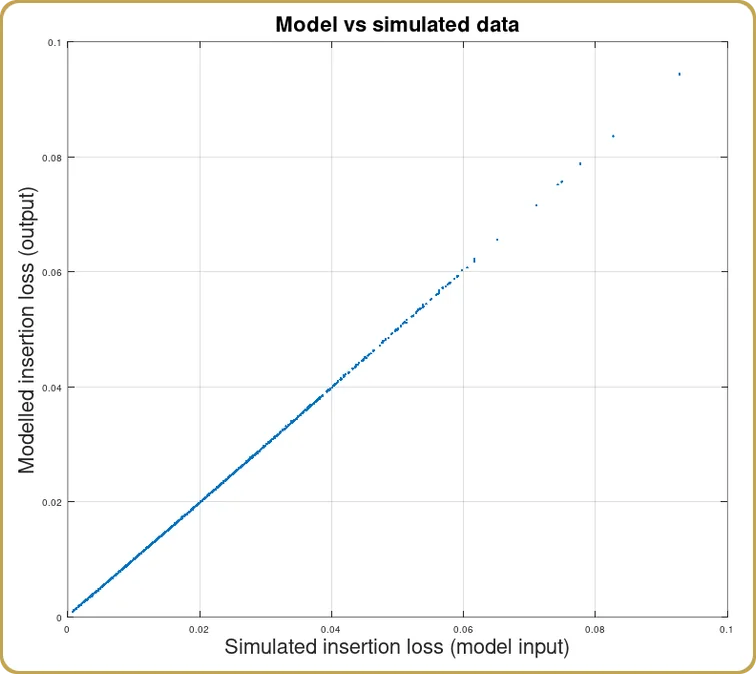
Comme prévu, nous avons obtenu une bonne corrélation entre les simulations et l'expansion du modèle. Puisque l'optique physique n'est décrite que par l'intégrale de recouvrement, cela était à prévoir. Après tout, il est censé s'agir d'un exemple à tirer.
Nous pouvons également examiner dans quelle mesure cette corrélation est due au terme linéaire,
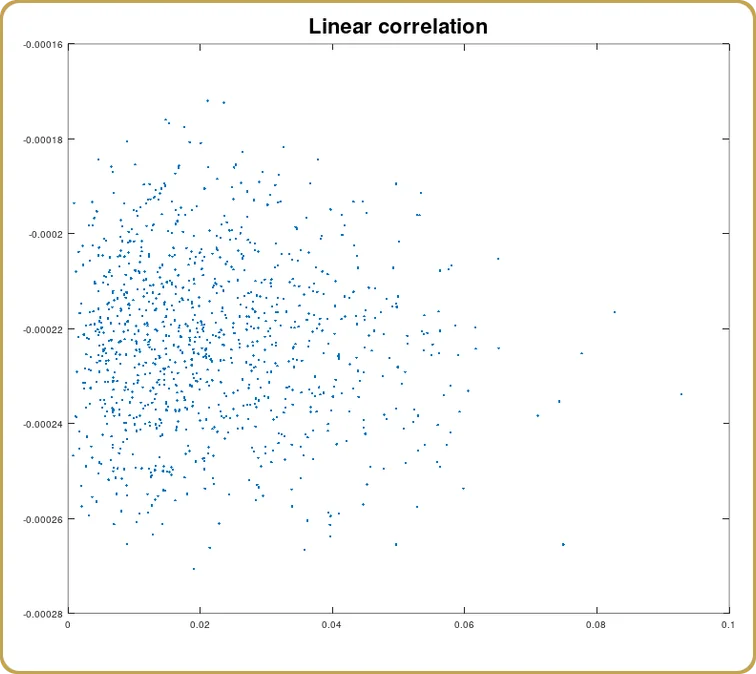
Et encore une fois, comme prévu, la corrélation est nulle (statistiquement). Nous avons modélisé quelque chose qui a un minimum à zéro aberration. On s'attend à ce que la partie linéaire disparaisse. Alors maintenant, examinons le terme au carré.
J'espère qu'il est maintenant évident que nous allons utiliser la décomposition en valeurs singulières, vous vous souvenez de la pilule rouge, n'est-ce pas ? Nous lançons donc notre H dans la SVD, et la première chose à examiner sont les valeurs singulières,
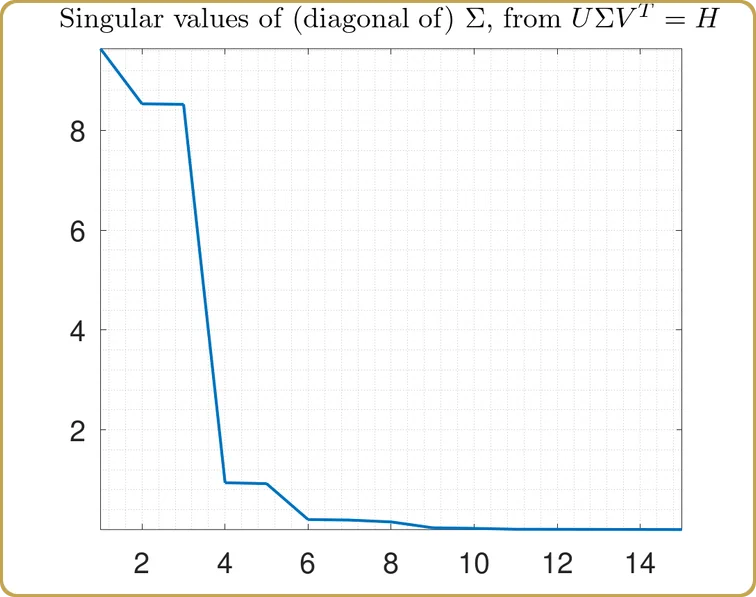
Les valeurs réelles sur l'axe Y ne sont finalement pas si intéressantes, elles dépendent du volume de notre hypercube de test, que nous avons utilisé pour échantillonner notre problème. Ce qui est plus intéressant, c'est la structure. Notre problème a été réduit à presque 3 variables indépendantes, plus 2 beaucoup moins importantes. Jetons un coup d'œil,
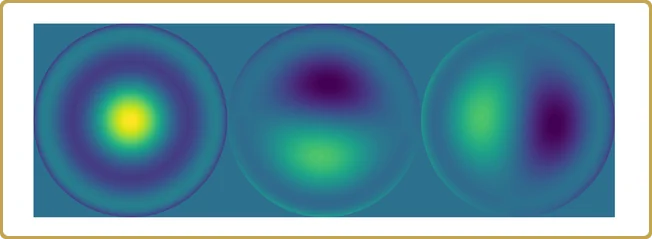
Il est temps de résumer.
Nous avons commencé avec 1024 valeurs simulées sur 15 dimensions de quelque chose dont nous (prétendions) ne rien savoir, et nous avons fini avec 3 contributions majeures à une propriété que nous voulions comprendre.
Il ne s'agit pas d'un résultat inhabituel dans ce type d'analyse. La corrélation n'est peut-être pas aussi bonne que dans cet exemple construit, mais avec une certaine transformation des données, le modèle de second ordre peut capturer essentiellement toute la variance de la simulation.
Peut-être que l'aspect le plus précieux de ce type d'analyse est que nous pouvons prendre en compte un nombre beaucoup plus important de degrés de liberté et ne pas nous limiter par notre capacité à démêler la complexité, ou pour reprendre la métaphore de la carte, il n'y a pas d'arbres. Des forêts et des collines est tout ce que nous voyons. De ce point de vue, la vue d'ensemble est tout ce qu'il y a, et tout ce que nous avons payé pour cela, c'est du temps de calcul.
Boîte à outils de l'ingénieur système
Il existe un outil pratique ici, pour les ingénieurs systèmes qui ont juste besoin d'un moyen de capturer une parmi de nombreuses pièces mobiles dans leur feuille Excel (généralement assez grande) d'arbitrages système.
Ce n’est pas tous les jours qu’on tombe sur une analyse aussi exemplaire que celle présentée ici. Si j’écris ces lignes, c’est parce que je viens justement d’en rencontrer une où il n’y a ni corrélation linéaire, ni corrélation d’ordre deux, mais où l’expansion complète permet tout de même de rendre compte de 96%-97% des données. Ce n’est pas rare lorsqu’on mélange des variables qui ne sont pas liées physiquement. En général, elles ne se modélisent pas bien ensemble.
Cependant, l'expansion a tout de même capturé des informations qui peuvent être utilisées lorsque nous, en tant qu'ingénieurs systèmes, devons arbitrer entre les paramètres que nous capturons dans nos simulations (disons) optiques et les effets que ces paramètres peuvent avoir sur d'autres propriétés du système. De nombreux exemples de ce type.
Aller plus loin
Pourquoi nous sommes-nous arrêtés à une expansion d'ordre 2 ? Eh bien, il y a des “raisons”. L'ordre suivant est décrit par un tenseur symétrique de rang 3. Nous pouvons encore extraire les composantes de ce tenseur parce que le problème des moindres carrés couplant ces composantes à nos données est toujours linéaire.
Il y a cependant certaines choses que nous perdons. Il n'y a pas de SVD pour les tenseurs, par exemple. Cependant, il y a eu des travaux mathématiques “récents” (si vous considérez 2005 comme récent, mais j'ai commencé avant 2005, donc), qui peuvent offrir des perspectives supplémentaires sur les propriétés des systèmes complexes, tels que les valeurs propres et les vecteurs propres pour les tenseurs.
Si vous trouvez cela trop ésotérique, et je comprends tout à fait si c'est le cas, un développement d'ordre 3 est garanti pour capturer plus de variance dans vos données qu'un développement d'ordre deux. Si vous avez juste besoin de cette fonction magique dans votre feuille Excel, au moins vous pouvez l'avoir.