



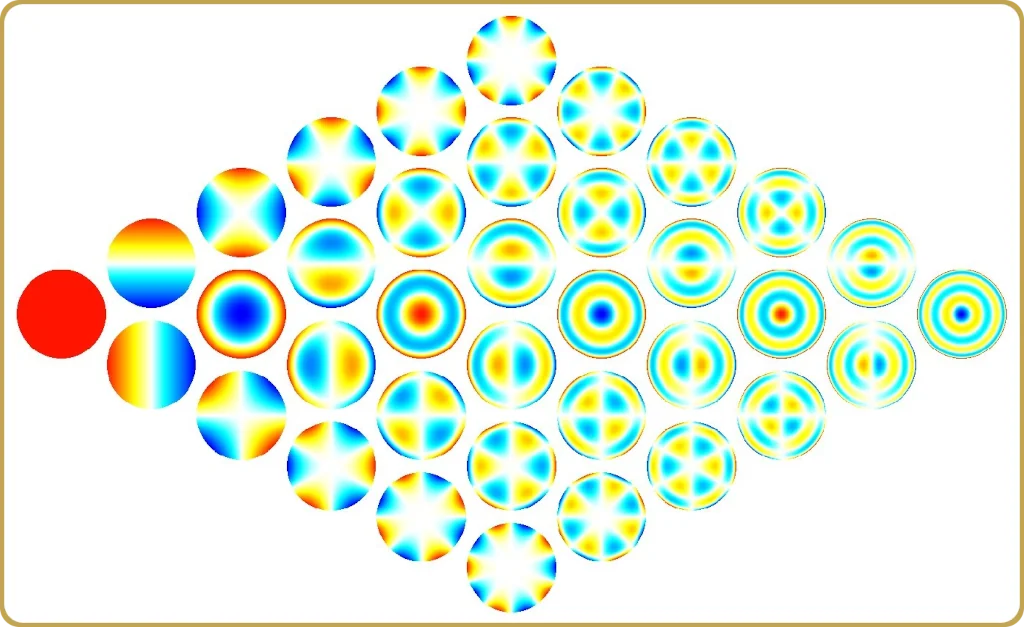
The Zernike polynomials, we all recognize them, and they are the language we often talk when we describe optical systems. But are they always the right language?
Is there a wrong language? Eventually, we would try to push a design to zero, and we may think it doesn’t matter. But the way we approach zero does matter.
What if we cannot get to zero, or in tolerancing, we can choose to push this or that term, but not both? How do we choose? If we are making a telescope, the case is clear. We want to minimize the variance of the wavefront and, by that, maximize the Strehl ratio. Very clearly derived in Born & Wolf. This is where the Zernike language is the right choice.
However, what if the property we are interested in is not derived from the variance? How do we know?
An analysis that can be employed is to find the MacLaurin expansion of the property of interest to second order using the Zernike polynomial as (say) probes or simply free parameters. One can use a Monte Carlo approach or Latin Hypercube Sampling approach to this, and which one is the best is a discussion to have elsewhere. However, once we have done that, we can find the c (offset), v (linear), and A (square) dependence that makes the best fit to the data, and this fit can be very good.
If A turns out not to be diagonal in this expansion, then the Zernike polynomials are not the right language because it does not follow that minimizing one of the coefficients always improves our property of interest. In this case, diagonalizing A will give us a new orthogonal basis.
However, before we ask the question which of the terms to minimize, but in the new base, what about the linear term v. The answer to that is, it depends.
There is obviously the possibility to look at the solution to f = 0, and if this solution is within the validity range of the expansion, we have probably found a non-trivial solution where non-zero aberrations generate zero error. This does happen (but is unusual), but quite often either v is essentially zero or the solution to f = 0 is not within the range of the expansion, mostly because v is residual from the fitting process.
When the linear term v is zero, we would now ask the same question as we did initially: should we improve this or that term in the new base? The answer is, it doesn’t matter because in the new base, the terms are independent, and we can choose to improve the one that provides the highest effect.
Arguably, this is somewhat esoteric, but given that we have the models of our optical system and the property of interest, probing 15-20 free parameters using a few thousand simulations may be entirely feasible and provides valuable insights into the fundamentals of the optical system. Often, this can be done in under a day if we already have the models in place. On the GPU, even faster than that.
But the really deep point is that, once we see how things work, we can feed it back into our top-level design. Example: We should always avoid linear sensitivities. It is a signal that we are possibly doing something wrong. It happens that this is unavoidable. Then it is what it is, but if this comes up as a surprise, it’s definitely something to feed back to our top-level system design to see if it’s not something that can be eliminated.